Program 1
Introduction
The purpose of this assignment is to give you practice writing functions and working with arrays (ArrayList actually).
You should spend at least one hour reading through this handout to make sure you understand what is required, so that you don't waste your time going in circles, or worse yet, hand in something you think is correct and find out later that you misunderstood the specifications. Highlight the handout, scribble on it, and find all the things you're not sure about as soon as possible.
Authorship Detection
Automated authorship detection is the process of using a computer program to analyze a large collection of texts, one of which has an unknown author, and making guesses about the author of that unattributed text. The basic idea is to use different statistics from the text -- called "features" in the machine learning community -- to form a linguistic "signature" for each text. One example of a simple feature is the number of words per sentence. Some authors may prefer short sentences while others tend to write sentences that go on and on with lots and lots of words and not very concisely, just like this one. Once we have calculated the signatures of two different texts we can determine their similarity and calculate a likelihood that they were written by the same person.
Automated authorship detection has uses in plagiarism detection, email-filtering, social-science research and as forensic evidence in court cases. Also called authorship attribution, this is a current research field and the state-of-the-art linguistic features are considerably more complicated than the five simple features that we will use for our program. But even with our very basic features and simplifications, your program may still be able to make some reasonable predictions about authorship.
We have begun a program that guesses the author of a text file based on comparing it to a set of linguistic signatures, FindAuthor.java. You can find that file and others you will need in the prog1.zip file in the xxx files folder. This program runs, but does almost nothing, because many of the functions' bodies do little or nothing. Your task is to complete the program by filling in the missing pieces.
An Overview: How the program works
The program expects to find two strings on the command line: the first is the name of a file of text whose authorship is unknown (the mystery file) and the second is the name of a directory of files, each containing one linguistic signature.
The program calculates the linguistic signature for the mystery file and then calculates scores indicating how well the mystery file matches each signature file in the directory. The author from the signature file that best matches the mystery file is reported.
Some Definitions: What really is a sentence?
Before we go further, it will be helpful to agree on what we will call a sentence, a word and a phrase. Let's define a token to be a string that you get from calling the method next() on a Scanner object. We define a word to be a non-empty token from the file that contains at least one letter (a-z or A-Z) or a digit (0-9) or the '_' character and the first and last symbols in the word are also from that same set (a-z, A-Z, 0-9, or _). You'll find the "words" in a file by using in.next() to find the tokens and then removing the leading and trailing non-word symbols from the words using the cleanUp function that we provided in FindAuthor.java. If after calling cleanUp the resulting word is an empty string, then it isn't considered a word. Notice that cleanUp converts the word to lowercase. This means that once they have been cleaned up, the strings/tokens yes, Yes and YES! will all be the same.
For the purposes of this assignment, we will consider a sentence to be a sequence of tokens where (1) it is terminated by a token ending in one of the characters ! ? . or the end of the file, (2) at least one of the tokens is a word. Consider this file. Remember that a file is just a linear sequence of characters, even though it looks two dimensional. This file contains these characters (the two character sequence \n is called an escape sequence and stands for a newline character):
this is the\nfirst sentence. Isn't\nit? Yes ! !! This \n\nlast bit :) is also a sentence, but \nwithout a terminator other than the end of the file\n
By our definition, there are four "sentences" in it:
| Sentence 1 |
"this is the\nfirst sentence." |
| Sentence 2 |
"Isn't\nit?" |
| Sentence 3 |
"Yes !" |
| Sentence 4 |
"This \n\nlast bit :) is also a sentence, but \nwithout a terminator other than the end of the file" |
Notice that:
- The last sentence was not terminated by a character; it finishes with the end of the file.
- Sentences can span multiple lines of the file.
Phrases are defined as non-empty sections of sentences that are separated by tokens ending in colons, commas, or semi-colons. The sentence prior to this one has three phrases by our definition. This sentence right here only has one (because we don't separate phrases based on parentheses).
We realize that these are not the correct definitions for sentences, words or phrases but using them will make the assignment easier. More importantly, it will make your results match what we are expecting when we test your code. You may not "improve" these definitions or your assignment will be marked as incorrect.
Linguistic features we will calculate
The first linguistic feature recorded in the signature is the average word length. This is simply the average number of characters per word, calculated after the punctuation has been stripped using the already-written cleanUp function. In the sentence prior to this one, the average word length is 5.909. Notice that the comma and the final period are stripped but the hyphen inside "already-written" is counted. That's fine. You must not change the cleanUp function that does punctuation stripping.
Type-Token Ratio is the number of different words used in a text divided by the total number of words. It's a measure of how repetitive the vocabulary is. Again you must use the provided cleanUp function so that "this","This","this," and "(this" are not counted as different words.
Hapax Legomana Ratio is similar to Type-Token Ratio in that it is a ratio using the total number of words as the denominator. The numerator for the Hapax Legomana Ratio is the number of words occurring exactly once in the text. In your code for this function you must not use a standard Java class (or one you find on the web) that keeps a count of the frequency of each word in the text. Instead use this approach: As you read the file, keep two lists (ArrayList). The first contains all the words that have appeared at least once in the text and the second has all the words that have appeared at least twice in the text. Of course, the words on the second list must also appear on the first. Once you've read the whole text, you can use the two lists to calculate the number of words that appeared exactly once.
The fourth linguistic feature your code will calculate is the average number of words per sentence.
The final linguistic feature is a measure of sentence complexity and is the average number of phrases per sentence.
Being Efficient
The design for this program is to read the tokens into an ArrayList<String> and then make repeated passes over the array, once for each feature. This would require a very large amount of memory for a large file but is faster than reading the file over and over again. This is an often found tradeoff being made between space and speed.
There are other ways where our assignment design isn't very efficient. For example, having the different linguistic features calculated by separate functions means that our program has to keep going over the text file doing many of the same actions (cleaning words and counting them) for each feature. This is inefficient if we are certain that anyone using our code would always be calculating all the features. However, our design allows another program to import our module and efficiently calculate a single linguistic feature without calculating the others. It also makes the code easier to understand, which in today's computing environment is often more important than efficiency.
Signature Files
We have created a set of signature files for you to use that have a fixed format. They are in the Resources/program 3 files/signatureFiles folder. The first line of each file is the name of the author and the next five lines each contain a single real number. These are values for the five linguistic features in the following order:
- Average Word Length
- Type-Token Ratio
- Hapax Legomana Ratio
- Average Sentence Length
- Sentence Complexity
You are welcome to create additional signature files for testing your code and for fun, but you must not change this format. Our testing of your program will depend on its ability to read the required signature-file format.
Determining the best match
In order to determine the best match between an unattributed text and the known signatures, the program uses the function compareSignatures which calculates and returns a measure of the similarity of two linguistic signatures. You could imagine developing some complicated schemes but our program will do almost the simplest thing imaginable. The similarity of signatures a and b will be calculated as the sum of the differences on each feature, but with each difference multiplied by a "weight" so that the influence of each feature on the total score can be controlled. In other words, the similarity of signatures a and b (Sab) is the sum over all five features of: the absolute value of the feature difference times the corresponding weight for that feature. The equation below expresses this definition mathematically: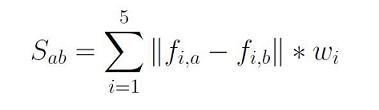
where fi,x is the value of feature i in signature x and wi is the weight associated with feature i.
The example below illustrates. Each row concerns one of the five features. Suppose signature 1 and signature 2 are as shown in columns 2 and 3, and the features are weighted as shown in column 4. The final column shows the contribution of each feature to the overall sum, which is 12. It represents the similarity of signatures 1 and 2.
| Feature number | Value of feature in signature 1 | Value of feature in signature 2 | Weight of feature | Contribution of this feature to the sum |
| 1 | 4.4 | 4.3 | 11 | abs(4.4-4.3)*11 = 1.1 |
| 2 | 0.1 | 0.1 | 33 | abs(0.1-0.1)*33 = 0 |
| 3 | 0.05 | 0.04 | 50 | abs(0.05-0.04)*50 = .5 |
| 4 | 10 | 16 | 0.4 | abs(10-16)*0.4 = 2.4 |
| 5 | 2 | 4 | 4 | abs(2-4)*4 = 8 |
| SUM | 12 |
Notice that if signatures 1 and 2 were exactly the same on every feature, the similarity would add up to zero. (It may have made sense to call this "difference" rather than similarity.) Notice also that if they are different on a feature that is weighted higher, there overall similarity value goes up more than if they are different on a feature with a low weight. This is how weights can be used to tune the importance of different features.
You are required to complete function compareSignatures according to the block comment and you must not change the header. Notice that the list of weights is provided to the function as a parameter. We have already set the weights that your program will use (see the main method) so you don't need to play around trying different values.
Additional requirements
- Where a block comment says a function can assume something about a parameter (e.g., it might say "text is a non-empty list") the function should not check that this thing is actually true. Instead, when you call the function make sure that it is indeed true.
- Do not change any of the existing code. Add to it as specified in the comments.
- Do not add or modify any user input or output except of course during testing you may have additional output. Just be sure and remove or comment it out before submitting the program.
Getting Started
The programs you submit this quarter should be original programs created just for this class. It is NOT acceptable to submit programs that you (or someone else) has written previously. If you incorporate any portions of programs written by someone else, or by you for a prior course or assignment, then that should be clearly noted in the program via comments. (See "Giving Credit Where Credit is Due".)
Here is our suggestion for steps to follow.
Principles:
- To avoid getting overwhelmed, deal with one function at a time. Start with functions that don't call any other functions; this will allow you to test them right away. The steps listed below give you a reasonable order in which to write the functions.
- For each function that you write, plan test cases for that function and actually write the JUnit test cases to implement those tests before you write the function. It is hard to have the discipline to do this, but you will have a huge advantage over your peers if you do. (From the original version of this assignment. For you, the tests have been written already in FindAuthorTest.java. Might be a good idea to look at the tests for the function you are writing and make sure you understand what they are testing.)
- As you write each function, begin by designing it in English, using only a few sentences. If your design is longer than that, shorten it by describing the steps at a higher level that leaves out some of the details. When you translate your design into Java, look for steps that are described at such a high level that they don't translate directly into Java. If need be, design a helper function for each of these, and put a call to the helpers into your code. Don't forget to write a great block comment for each helper!
Steps:
Here is a good order in which to solve the pieces of this assignment.
- Read this handout thoroughly and carefully, making sure you understand everything in it, particularly the different linguistic features.
- Download prog1.zip from Files/Program Files and open it up. It contains the starter source already configured as a DrJava project in a folder names src, the "mystery" files your program needs to properly identify (the actual author names are in the files so not really a mystery), and the signatures (folder sigs) of a number of authors. The project should have three files, FindAuthor.java, Signature.java, and FindAutherTest.java.
- Read the starter code to get an overview of what you will be writing. It is not necessary at this point to understand every detail of the functions we have provided in order to make progress on this assignment.
- Write, and test functions for the first three linguistic features:
averageWordLength,typeTokenRatio, andhapaxLegomanaRatio. - Write and test function
averageSentenceLength. - Complete
avgSentenceComplexityand finallycompareSignatures. - Now you have implemented all the functions, your program should be passing all tests in
FindAuthorTest. - You are now ready to run the full author detection program: run
findAuthor. To do this you will need to set up a folder that contains only valid linguistic signature files. We are providing a set of these in the sigs folder of prog1.zip. You'll also want some mystery text files to analyze. They are also in the prog1.zip you downloaded and expanded in step 2. To run your program on an actual file in the interactions pane of DrJava or at a command line type:java FindAuthor ../mystery1.txt ../sigs
of course changing mystery1.txt as needed for the other test files or for your own file you want to run it on.
Testing your code
We are providing the JUnit test code FindAuthorTest that checks that the required functions satisfy some of the requirements. Your program must work with and pass all of these tests. Note that your class MUST BE NAMED FindAuthor.
If any of the FindAuthorTests do not pass then your code is not following the assignment specifications correctly and will be marked as incorrect. Go back and fix the error(s).
In addition to passing the JUnit tests in FindAuthorTest you should test your program with the signature files and mystery text files we have provided.
What to Submit
For this assignment submit only your modified FindAuthor.java file using CrowdGrader.
It won't hurt if you both submit the same .java file to CrowdGrader. Better safe than sorry. You might want to watch your partner do the submission to make sure it is successful. You are responsible even if your partner is the one doing the submission.
Also, don't forget to have BOTH partners submit a log in Canvas (by pasting into the submission text field) using one of the log templates from this file. Late submissions may be made in Canvas by attaching the FindAuthor.java file up until the start of class following the due date.
Grading
1 point for each function (there are 7) that passes all of its JUnit tests (typically 2 or 3 tests per function).
0.5 points for each mystery file correctly identified (up to a max of 2 points)
1 point for style. 1/2 point will be deducted for each type of style deficiency (e.g. inadequate comments, non-descriptive variable names). style guidelines